How a Large Language Model works
A deep dive into the real mechanics — and how this project simulates them.
🧠 1. What is a Large Language Model?
A Large Language Model (LLM) is a neural network trained to predict the most likely next word (or token) given everything that came before it.
Modern LLMs are built on the Transformer architecture (introduced by Google in 2017).
The pipeline from text to answer involves four conceptually distinct stages: tokenize → embed → process → generate.
✂️ 2. Tokenization — text becomes numbers
Neural networks can only process numbers, so the first step is converting text into a sequence of integers called token IDs.
Real LLMs: Byte-Pair Encoding (BPE)
Most modern LLMs use BPE or a variant (SentencePiece, WordPiece).
Why sub-word tokenization?
Pure word-based tokenizers fail on rare words and typos.
SimpleTokenizer uses a regex to split on whitespace and punctuation.
🔢 3. Embeddings — numbers become vectors
A token ID like 2963 is just an index. Before the Transformer can work with it, each ID is converted into a dense vector called an embedding.
Think of an embedding as a point in a very high-dimensional space.
👁️ 4. Attention — context shapes meaning
The core innovation of the Transformer is self-attention.
Concretely: for each token, three vectors are computed — Query (Q), Key (K), and Value (V).
In plain English: "The word 'it' in 'The animal was tired because it…' attends strongly to 'animal'."
Multi-head attention
In practice, attention is computed h times in parallel with different learned projections (the "heads").
⚡ 5. The generation loop — one token at a time
LLMs generate text autoregressively: one token at a time.
LLMCore.generate() does iterate token-by-token.
🌡️ 6. Softmax & temperature — shaping the distribution
After the forward pass, the model has a raw score (logit) for every token. Softmax converts those scores into a proper probability distribution.
What does temperature do?
Temperature T is applied as a divisor before the exponential:
- T = 1.0 — the model's learned distribution, unchanged.
Here's an example showing how temperature changes a concrete distribution:
Other sampling strategies
Temperature is often combined with:
- Top-k sampling
🤖 7. Agents & tool use
A bare LLM is a text-in / text-out function. Agents extend LLMs with the ability to use tools and take multi-step actions.
How tool use works in real systems
Modern frameworks (OpenAI function calling, Anthropic tool use) work roughly like this:
- A list of available tools is prepended to the system prompt.
Chain-of-thought reasoning
Before deciding which tool to call, frontier models often produce a reasoning trace.
ReasoningAgent uses simple rule-based heuristics.
CalculatorTool uses Python's eval().
🔮 8. What this simulation actually does
The full pipeline, from the moment you hit Ask → to the moment the trace is ready:
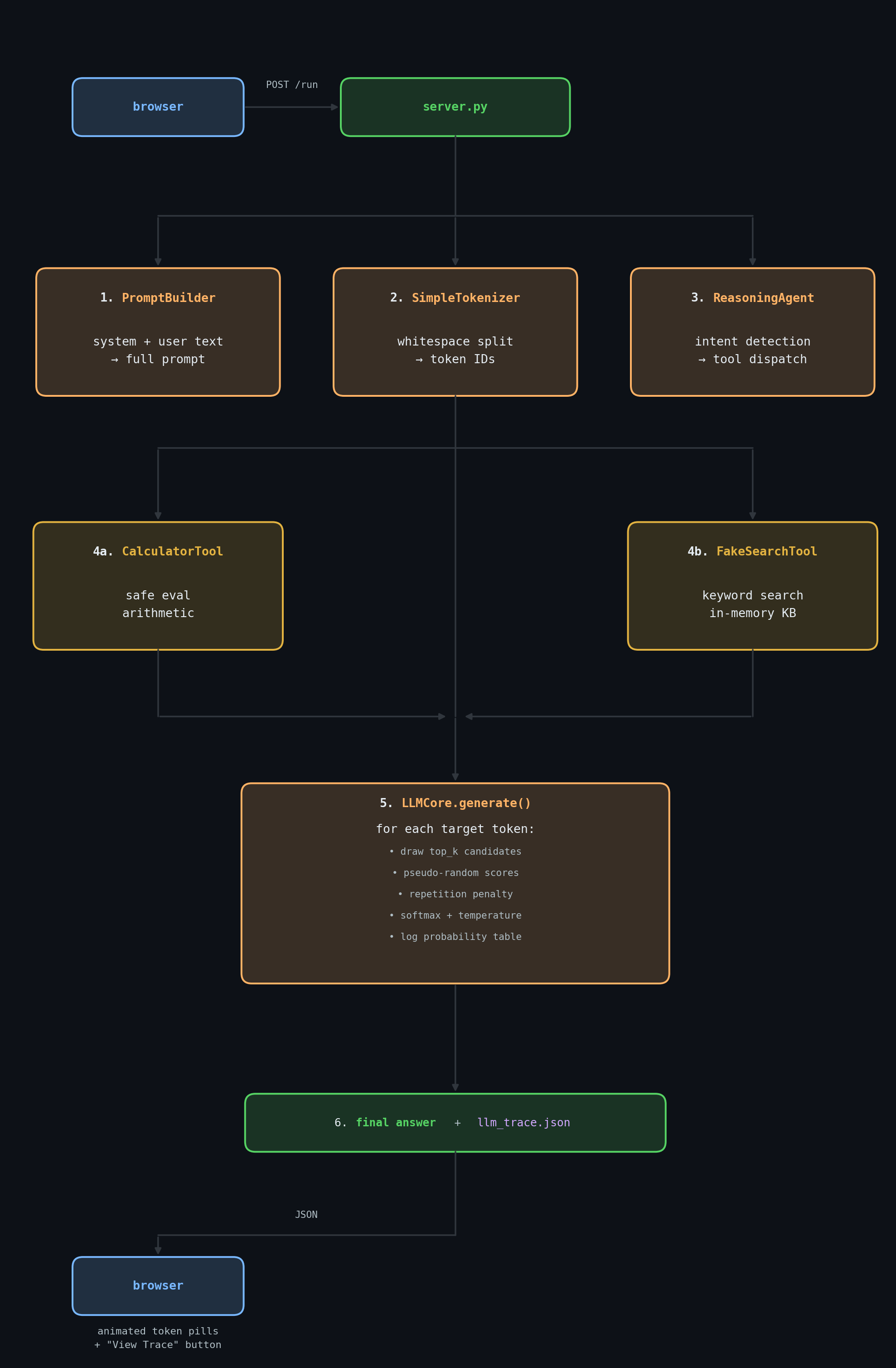
Every one of these steps writes a TraceStep into the append-only Trace object.
Real vs. simulated — side by side
| Aspect | Real LLM | This simulation |
|---|---|---|
| Tokenizer | BPE / WordPiece, fixed vocabulary of 32k–200k tokens | Whitespace + punctuation regex, dynamic vocabulary |
| Embeddings | Learned dense vectors (768–8192 dims) | Not implemented — skipped |
| Attention | Multi-head self-attention across full context | Not implemented — context is just a list of IDs |
| Token scores | Output of the final linear layer (learned logits) | Pseudo-random scores + repetition penalty heuristic |
| Softmax | Applied to all ~100k logits | Applied to top_k=6 candidates — same math, smaller scale |
| Temperature | Scales logits before softmax | Same formula, same effect — fully functional |
| Sampling | Draw from distribution (top-p / top-k) | Target token is forced (but probability table is real) |
| Tool use | LLM outputs structured JSON; framework parses it | Rule-based intent detection; same logical structure |
| Reasoning trace | Hidden (or via CoT prompting / o-series) | Explicit, logged to trace at every step |
| Observability | Black box (unless you add logging) | Every decision visible in the Trace Viewer |
⚠️ 9. What this simulation cannot show
This project is deliberately simplified for educational purposes. Here are the most important things that are not represented:
- Emergent capabilities
Ready to see the pipeline in action?
Ask a question →